Libevent源码中有一个queue.h文件,位于compat/sys目录下。该文件里面定义了5个数据结构,其中TAILQ_QUEUE是使得最广泛的。本文就说一下这个数据结构。
队列结构体:
TAILQ_QUEUE由下面两个结构体一起配合工作。
#define TAILQ_HEAD(name, type) \
struct name { \
struct type *tqh_first; /* first element */ \
struct type **tqh_last; /* addr of last next element */ \
}
//和前面的TAILQ_HEAD不同,这里的结构体并没有name.即没有结构体名。
//所以该结构体只能作为一个匿名结构体。所以,它一般都是另外一个结构体
//或者共用体的成员
#define TAILQ_ENTRY(type) \
struct { \
struct type *tqe_next; /* next element */ \
struct type **tqe_prev; /* address of previous next element */ \
}
由这两个结构体配合构造出来的队列一般如下图所示:
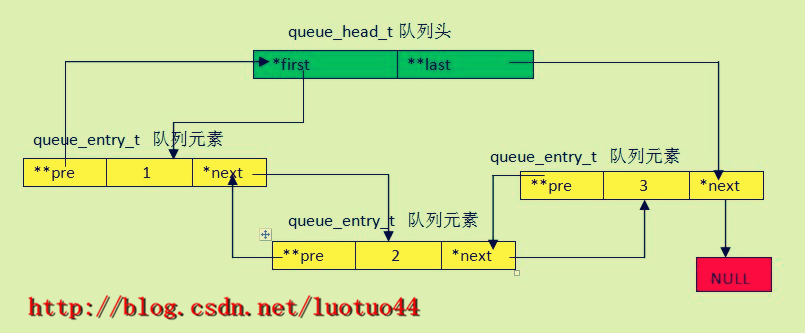
图中,一级指针指向的是queue_entry_t这个结构体,即存储queue_entry_t这个结构体的地址值。二级指针存储的是一级地址变量的地址值。所以二级指针指向的是图中的一级指针,而非结构体。图中的1,2, 3为队列元素保存的一些值。
队列操作宏函数以及使用例子:
除了这两个结构体,在queue.h文件中,还为TAILQ_QUEUE定义了一系列的访问和操作函数。很不幸,它们是一些宏定义。这里就简单贴几个函数(准确来说,不是函数)的代码。#define TAILQ_FIRST(head) ((head)->tqh_first)
#define TAILQ_NEXT(elm, field) ((elm)->field.tqe_next)
#define TAILQ_INIT(head) do { \
(head)->tqh_first = NULL; \
(head)->tqh_last = &(head)->tqh_first; \
} while (0)
#define TAILQ_INSERT_TAIL(head, elm, field) do { \
(elm)->field.tqe_next = NULL; \
(elm)->field.tqe_prev = (head)->tqh_last; \
*(head)->tqh_last = (elm); \
(head)->tqh_last = &(elm)->field.tqe_next; \
} while (0)
#define TAILQ_REMOVE(head, elm, field) do { \
if (((elm)->field.tqe_next) != NULL) \
(elm)->field.tqe_next->field.tqe_prev = \
(elm)->field.tqe_prev; \
else \
(head)->tqh_last = (elm)->field.tqe_prev; \
*(elm)->field.tqe_prev = (elm)->field.tqe_next; \
} while (0)
这些宏是很难看的,也没必要直接去看这些宏。下面来看一个使用例子。有例子更容易理解。
//队列中的元素结构体。它有一个值,并且有前向指针和后向指针
//通过前后像指针,把队列中的节点(元素)连接起来
struct queue_entry_t
{
int value;
//从TAILQ_ENTRY的定义可知,它只能是结构体或者共用体的成员变量
TAILQ_ENTRY(queue_entry_t)entry;
};
//定义一个结构体,结构体名为queue_head_t,成员变量类型为queue_entry_t
//就像有头节点的链表那样,这个是队列头。它有两个指针,分别指向队列的头和尾
TAILQ_HEAD(queue_head_t, queue_entry_t);
int main(int argc, char **argv)
{
struct queue_head_t queue_head;
struct queue_entry_t *q, *p, *s, *new_item;
int i;
TAILQ_INIT(&queue_head);
for(i = 0; i < 3; ++i)
{
p = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
p->value = i;
//第三个参数entry的写法很怪,居然是一个成员变量名(field)
TAILQ_INSERT_TAIL(&queue_head, p, entry);//在队尾插入数据
}
q = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
q->value = 10;
TAILQ_INSERT_HEAD(&queue_head, q, entry);//在队头插入数据
//现在q指向队头元素、p指向队尾元素
s = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
s->value = 20;
//在队头元素q的后面插入元素
TAILQ_INSERT_AFTER(&queue_head, q, s, entry);
s = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
s->value = 30;
//在队尾元素p的前面插入元素
TAILQ_INSERT_BEFORE(p, s, entry);
//现在进行输出
//获取第一个元素
s = TAILQ_FIRST(&queue_head);
printf("the first entry is %d\n", s->value);
//获取下一个元素
s = TAILQ_NEXT(s, entry);
printf("the second entry is %d\n\n", s->value);
//删除第二个元素, 但并没有释放s指向元素的内存
TAILQ_REMOVE(&queue_head, s, entry);
free(s);
new_item = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
new_item->value = 100;
s = TAILQ_FIRST(&queue_head);
//用new_iten替换第一个元素
TAILQ_REPLACE(&queue_head, s, new_item, entry);
printf("now, print again\n");
i = 0;
TAILQ_FOREACH(p, &queue_head, entry)//用foreach遍历所有元素
{
printf("the %dth entry is %d\n", i, p->value);
}
p = TAILQ_LAST(&queue_head, queue_head_t);
printf("last is %d\n", p->value);
p = TAILQ_PREV(p, queue_head_t, entry);
printf("the entry before last is %d\n", p->value);
}
例子并不难看懂。这里就不多讲了。
展开宏函数:
下面把这些宏翻译一下(即展开),显示出它们的本来面貌。这当然不是用人工方式去翻译。而是用gcc 的-E选项。
阅读代码时要注意,tqe_prev和tqh_last都是二级指针,行为会有点难理解。平常我们接触到的双向链表,next和prev成员都是一级指针。对于像链表A->B->C(把它们想象成双向链表),通常B的prev指向A这个结构体本身。此时,B->prev->next指向了本身。但队列Libevent的TAILQ_QUEUE,B的prev是一个二级指向,它指向的是A结构体的next成员。此时,*B->prev就指向了本身。当然,这并不能说用二级指针就方便。我觉得用二级指针理解起来更难,编写代码更容易出错。
//队列中的元素结构体。它有一个值,并且有前向指针和后向指针
//通过前后像指针,把队列中的节点连接起来
struct queue_entry_t
{
int value;
struct
{
struct queue_entry_t *tqe_next;
struct queue_entry_t **tqe_prev;
}entry;
};
//就像有头节点的链表那样,这个是队列头。它有两个指针,分别指向队列的头和尾
struct queue_head_t
{
struct queue_entry_t *tqh_first;
struct queue_entry_t **tqh_last;
};
int main(int argc, char **argv)
{
struct queue_head_t queue_head;
struct queue_entry_t *q, *p, *s, *new_item;
int i;
//TAILQ_INIT(&queue_head);
do
{
(&queue_head)->tqh_first = 0;
//tqh_last是二级指针,这里指向一级指针
(&queue_head)->tqh_last = &(&queue_head)->tqh_first;
}while(0);
for(i = 0; i < 3; ++i)
{
p = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
p->value = i;
//TAILQ_INSERT_TAIL(&queue_head, p, entry);在队尾插入数据
do
{
(p)->entry.tqe_next = 0;
//tqh_last存储的是最后一个元素(队列节点)tqe_next成员
//的地址。所以,tqe_prev指向了tqe_next。
(p)->entry.tqe_prev = (&queue_head)->tqh_last;
//tqh_last存储的是最后一个元素(队列节点)tqe_next成员
//的地址,所以*(&queue_head)->tqh_last修改的是最后一个
//元素的tqe_next成员的值,使得tqe_next指向*p(新的队列
//节点)。
*(&queue_head)->tqh_last = (p);
//队头结构体(queue_head)的tqh_last成员保存新队列节点的
//tqe_next成员的地址值。即让tqh_last指向tqe_next。
(&queue_head)->tqh_last = &(p)->entry.tqe_next;
}while(0);
}
q = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
q->value = 10;
//TAILQ_INSERT_HEAD(&queue_head, q, entry);在队头插入数据
do {
//queue_head队列中已经有节点(元素了)。要对第一个元素进行修改
if(((q)->entry.tqe_next = (&queue_head)->tqh_first) != 0)
(&queue_head)->tqh_first->entry.tqe_prev = &(q)->entry.tqe_next;
else//queue_head队列目前是空的,还没有任何节点(元素)。修改queue_head即可
(&queue_head)->tqh_last = &(q)->entry.tqe_next;
//queue_head的first指针指向要插入的节点*q
(&queue_head)->tqh_first = (q);
(q)->entry.tqe_prev = &(&queue_head)->tqh_first;
}while(0);
//现在q指向队头元素、p指向队尾元素
s = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
s->value = 20;
//TAILQ_INSERT_AFTER(&queue_head, q, s, entry);在队头元素q的后面插入元素
do
{
//q不是最后队列中最后一个节点。要对q后面的元素进行修改
if (((s)->entry.tqe_next = (q)->entry.tqe_next) != 0)
(s)->entry.tqe_next->entry.tqe_prev = &(s)->entry.tqe_next;
else//q是最后一个元素。对queue_head修改即可
(&queue_head)->tqh_last = &(s)->entry.tqe_next;
(q)->entry.tqe_next = (s);
(s)->entry.tqe_prev = &(q)->entry.tqe_next;
}while(0);
s = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
s->value = 30;
//TAILQ_INSERT_BEFORE(p, s, entry); 在队尾元素p的前面插入元素
do
{
//无需判断节点p前面是否还有元素。因为即使没有元素,queue_head的两个
//指针从功能上也相当于一个元素。这点是采用二级指针的一大好处。
(s)->entry.tqe_prev = (p)->entry.tqe_prev;
(s)->entry.tqe_next = (p);
*(p)->entry.tqe_prev = (s);
(p)->entry.tqe_prev = &(s)->entry.tqe_next;
}while(0);
//现在进行输出
// s = TAILQ_FIRST(&queue_head);
s = ((&queue_head)->tqh_first);
printf("the first entry is %d\n", s->value);
// s = TAILQ_NEXT(s, entry);
s = ((s)->entry.tqe_next);
printf("the second entry is %d\n\n", s->value);
//删除第二个元素, 但并没有释放s指向元素的内存
//TAILQ_REMOVE(&queue_head, s, entry);
do
{
if (((s)->entry.tqe_next) != 0)
(s)->entry.tqe_next->entry.tqe_prev = (s)->entry.tqe_prev;
else (&queue_head)->tqh_last = (s)->entry.tqe_prev;
*(s)->entry.tqe_prev = (s)->entry.tqe_next;
}while(0);
free(s);
new_item = (struct queue_entry_t*)malloc(sizeof(struct queue_entry_t));
new_item->value = 100;
//s = TAILQ_FIRST(&queue_head);
s = ((&queue_head)->tqh_first);
//用new_iten替换第一个元素
//TAILQ_REPLACE(&queue_head, s, new_item, entry);
do
{
if (((new_item)->entry.tqe_next = (s)->entry.tqe_next) != 0)
(new_item)->entry.tqe_next->entry.tqe_prev = &(new_item)->entry.tqe_next;
else
(&queue_head)->tqh_last = &(new_item)->entry.tqe_next;
(new_item)->entry.tqe_prev = (s)->entry.tqe_prev;
*(new_item)->entry.tqe_prev = (new_item);
}while(0);
printf("now, print again\n");
i = 0;
//TAILQ_FOREACH(p, &queue_head, entry)//用foreach遍历所有元素
for((p) = ((&queue_head)->tqh_first); (p) != 0;
(p) = ((p)->entry.tqe_next))
{
printf("the %dth entry is %d\n", i, p->value);
}
//p = TAILQ_LAST(&queue_head, queue_head_t);
p = (*(((struct queue_head_t *)((&queue_head)->tqh_last))->tqh_last));
printf("last is %d\n", p->value);
//p = TAILQ_PREV(p, queue_head_t, entry);
p = (*(((struct queue_head_t *)((p)->entry.tqe_prev))->tqh_last));
printf("the entry before last is %d\n", p->value);
}
代码中有一些注释,不懂的可以看看。其实对于链表操作,别人用文字说再多都对自己理解帮助不大。只有自己动手一步步把链表操作都画出来,这样才能完全理解。
特殊指针操作:
最后那两个操作宏函数有点难理解,现在来讲一下。在讲之前,先看一个关于C语言指针的例子。#include<stdio.h>
struct item_t
{
int a;
int b;
int c;
};
struct entry_t
{
int a;
int b;
};
int main()
{
struct item_t item = { 1, 2, 3};
entry_t *p = (entry_t*)(&item.b);
printf("a = %d, b = %d\n", p->a, p->b);
return 0;
}
代码输出的结果是:a = 2, b = 3
对于entry_t *p, 指针p指向的内存地址为&item.b。此时对于编译器来说,它认为从&item.b这个地址开始,是一个entry_t结构体的内存区域。并且把前4个字节当作entry_t成员变量a的值,后4个字节当作entry_t成员变量b的值。所以就有了a = 2, b = 3这个输出。
好了,现在开始讲解那两个难看懂的宏。先看一张图。
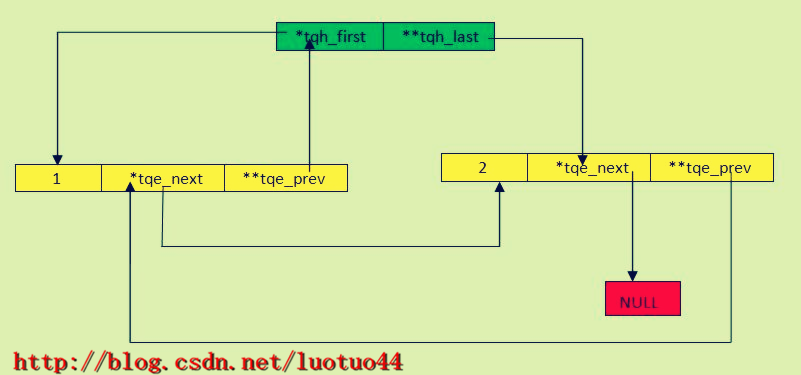
虽然本文最前面的图布局更好看一点,但这张图才更能反映文中这两个结构体的内存布局。不错,tqe_next是在tqe_prev的前面。这使得tqe_next、tqe_prev于tqh_first、tqh_last的内存布局一样。一级指针在前,二级指针在后。
现在来解析代码中最后两个宏函数。
队尾节点:
//p = TAILQ_LAST(&queue_head, queue_head_t); p = (*(((struct queue_head_t *)((&queue_head)->tqh_last))->tqh_last));
首先是(&queue_head)->tqh_last,它的值是最后一个元素的tqe_next这个成员变量的地址。然后把这个值强制转换成struct queue_head_t *指针。此时,相当于有一个匿名的struct queue_head_t类型指针q。它指向的地址为队列的最后一个节点的tqe_next成员变量的地址。无论一级还是二级指针,其都是指向另外一个地址。只是二级指针只能指向一个一级指针的地址。
此时,在编译器看来,从tqe_next这个变量的地址开始,是一个struct queue_head_t结构体的内存区域。并且可以将代码简写成:p = (*(q->tqh_last));
回想一下刚才的那个例子。q->tqh_last的值就是上图中最后一个节点的tqe_prev成员变量的值。所以*(q->tqh_last))就相当于*tqe_prev。注意,变量tqe_prev是一个二级指针,它指向倒数第二个节点的tqe_next成员。所以*tqe_prev获取了倒数第二个节点的tqe_next成员的值。它的值就是最后一个节点的地址。最后,将这个地址赋值给p,此时p指向最后一个节点。完成了任务。好复杂的过程。
前一个节点:
现在来看一下最后那个宏函数,代码如下:
//p = TAILQ_PREV(p, queue_head_t, entry); p = (*(((struct queue_head_t *)((p)->entry.tqe_prev))->tqh_last));注意,右边的p此时是指向最后一个节点(元素)的。所以(p)->entry.tqe_prev就是倒数第二个节点tqe_next成员的地址。然后又强制转换成struct queue_head_t指针。同样,假设一个匿名的struct queue_head_t *q;此时,宏函数可以转换成:
p = (*((q)->tqh_last));
同样,在编译器看来,从倒数第二个参数节点tqe_next的地址开始,是一个structqueue_head_t结构体的内存区域。所以tqh_last实际值是tqe_prev变量上的值,即tqe_prev指向的地址。*((q)->tqh_last)就是*tqe_prev,即获取tqe_prev指向的倒数第三个节点的tqe_next的值。而该值正是倒数第二个节点的地址。将这个地址赋值给p,此时,p就指向了倒数第二个节点。完成了TAILQ_PREV函数名的功能。
这个过程确实有点复杂。而且还涉及到强制类型转换。
其实,在TAILQ_LAST(&queue_head, queue_head_t);中,既然都可以获取最后一个节点的tqe_next的地址值,那么直接将该值 + 4就可以得到tqe_precv的地址值了(假设为pp)。有了该地址值pp,那么直接**pp就可以得到最后一个节点的地址了。代码如下:struct queue_entry_t **pp = (&queue_head)->tqh_last;
pp += 1; //加1个指针的偏移量,在32位的系统中,就等于+4
//因为这里得到的是二级指针的地址值,所以按理来说,得到的是一个
//三级指针。故要用强制转换成三级指针。
struct queue_entry_t ***ppp = (struct queue_entry_t ***)pp;
s = **ppp;
printf("the last is %d\n", s->value);
该代码虽然能得到正确的结果,但总感觉直接加上一个偏移量的方式太粗暴了。
有一点要提出,+1那里并不会因为在64位的系统就不能运行,一样能正确运行的。因为1不是表示一个字节,而是一个指针的偏移量。在64位的系统上一个指针的偏移量为8字节。这种”指针 + 数值”,实际其增加的值为:数值 + sizeof(*指针)。不信的话,可以试一下char指针、int指针、结构体指针(结构体要有多个成员)。
好了,还是回到最开始的问题上吧。这个TAILQ_QUEUE队列是由两部分组成:队列头和队列节点。在Libevent中,队列头一般是event_base结构体的一个成员变量,而队列节点则是event结构体。比如event_base结构体里面有一个struct event_list eventqueue;其中,结构体struct event_list如下定义://event_struct.h
TAILQ_HEAD (event_list, event);
//所以event_list的定义展开后如下:
struct event_list
{
struct event *tqh_first;
struct event **tqh_last;
};
在event结构体中,则有几个TAILQ_ENTRY(event)类型的成员变量。这是因为根据不同的条件,采用不同的队列把这些event结构体连在一起,放到一条队列中。