ORM是一种讨厌的反模式,违背了所有面向对象的原则。将对象分隔开并放入被动的数据包中。ORM没有理由存在任何应用中,无论是小的网络应用还是涉及增删改查上千张表的企业系统。用什么来替代它呢?SQL对象(SQL-speaking objects)。
ORM如何工作
Object-relational mapping(ORM)是一种链接关系型数据库和面向对象语言(比如Java)的技术。在各种语言中有大量ORM的实现;比如:Java中的Hibernate,Ruby on Rails中的ActiveRecord,PHP中的Doctrine,Python中的SQLAlchemy。在Java中,甚至把ORM设计作为JPA标准。
首先,让我们看看ORM如何工作。比如,我们用Java,PostgreSQL和Hibernate。我们在数据库有张表,叫 *post*:
| id | date | title |
|---|---|---|
| 9 | 10/24/2014 | How to cook a sandwich |
| 13 | 11/03/2014 | My favorite movies |
| 27 | 11/17/2014 | How much I love my job |
如果我们在Java应用中对这张表增删改查(CRUD:create, read, update, and delete).首先,我们创建一个 *Post* 类(很抱歉代码很长,我尽量简洁一点)
@Entity
@Table(name = "post")
public class Post {
private int id;
private Date date;
private String title;
@Id
@GeneratedValue
public int getId() {
return this.id;
}
@Temporal(TemporalType.TIMESTAMP)
public Date getDate() {
return this.date;
}
public Title getTitle() {
return this.title;
}
public void setDate(Date when) {
this.date = when;
}
public void setTitle(String txt) {
this.title = txt;
}
}
在Hibernate做任何操作前,我们要创建一个session工厂:
SessionFactory factory = new AnnotationConfiguration()
.configure()
.addAnnotatedClass(Post.class)
.buildSessionFactory();
这个工厂能在每次我们需要操作 *Post*对象时给我们”session”。任何有关session的操作应该包裹下面代码块:
Session session = factory.openSession();
try {
Transaction txn = session.beginTransaction();
// your manipulations with the ORM, see below
txn.commit();
} catch (HibernateException ex) {
txn.rollback();
} finally {
session.close();
}
当session准备就绪,下面是我们从数据库表中获取所有 *post*:
List posts = session.createQuery("FROM Post").list();
for (Post post : (List<Post>) posts){
System.out.println("Title: " + post.getTitle());
}
我认为到这就很简单了。Hibernate是一个强大的引擎,链接数据库,执行SQL *SELECT*请求,然后取得数据。然后实例化 *Post*对象并装填数据。当我们得到对象时,它已经有了数据,比如我们上面使用 *getTitle()。*
当我们想进行反向操作,将一个对象存入数据库,操作相同,顺序相反。我们先实例化 *Post*对象,装填数据,然后让Hibernate保存它:
Post post = new Post();
post.setDate(new Date());
post.setTitle("How to cook an omelette");
session.save(post);
这就是所有的ORM如何工作。基本原则总是一样的——ORM对象就是数据的信使。我们与ORM框架交互。框架与数据库交互。对象只是帮助我们向框架发送请求并处理响应。除了get和set,没有其他方法,我们甚至不知道数据库在哪。
这就是对象-关系映射如何工作。
你或许会问哪里有问题?到处!
ORM有什么问题?
讲真的,这有什么问题?Hibernate成为最受欢迎的Java库已有10多年,几乎所有处理SQL的应用都在使用它,每个Java教程都会介绍Hibernate(或其他ORM,比如TopLink和OpenJPA)作为数据库连接应用,它已成为一个标准。我还要认为它有问题吗?当然。
我想说整个ORM的构想就是有问题的,它的发明简直是面向对象编程里NULL指针之后的第二大错误。
事实上,我并不是第一个指出这个问题的人,有众多知名作者讨论这个话题,包括Martin Fowler写的OrmHate(虽然不是反对ORM,但是也值得关注),Jeff Atwood写的 Object-Relational Mapping Is the Vietnam of Computer Science,Ted Neward写的The Vietnam of Computer Science,Laurie Voss写的ORM Is an Anti-Pattern等等。
然而,我的论点不同于上面几位,尽管他们的论点实用又有根据,比如“ORM很慢”或“数据库升级困难”,他们没抓住重点。你可以在Bozhidar Bozhanov的ORM Haters Don’t Get It这篇博客中找到很棒的论点。
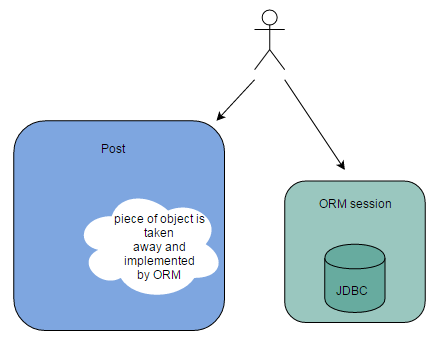
重点是ORM没有在对象中封装数据库的交互,而是把固定的数据和活动的交互分隔开。一部分在对象中储存数据,另一部分由ORM引擎实现(session工厂)来与数据库交互数据。上面这张图展示了ORM做了什么。
我作为 *post*数据的操作者,需要处理两个组件:一是ORM,二是返回的”删减版”(指只有get和set方法)对象。面向对象编程强调的是关注单一的切入点,也就是对象。但在ORM中,我需要关注两个切入点——ORM引擎和我们甚至不能称之为对象的”东西”。
因为这严重违背了面向对象的范式,我们可以从很多德高望重的论文中找到实用的解决方案,我可以再提供更多的解决方案。
SQL不再隐藏(SQL Is Not Hidden),ORM用户常使用SQL(或其他方言,比如HQL)。上面例子中,我们调用 *session.createQuery(“FROM Post”)* 来获取所有 *post*。即使这不是SQL,但很像SQL,所以关系模型并没有封装在对象中。反而暴露在整个应用中,每个人操作对象时无可避免的需要处理关系模型,来获取或存储数据。所以ORM并没有隐藏和包裹SQL,反而使其暴露在整个应用中。
难于测试。如果某个对象处理post的数组,它必须处理 *SessionFactory*的实例。我们如何mock这个依赖呢?看上面的代码,你就会意识到单元测试会有多繁琐和麻烦。相反,我们可以编写集成测试,用整个应用链接到虚构的测试PostgreSQL。这样,我们就不需要mock一个 *SessionFactory*,但这样的测试会很慢,更重要的是,我们虚构的和数据库无关这个对象会和数据库实例冲突。这是个可怕的设计。
我再次重申,ORM的实际问题就是这种后果,本质缺点就是ORM将对象分隔开,严重违反了对象的含义。
SQL对象(SQL-Speaking Objects)
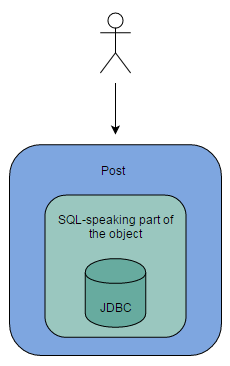
有什么解决方案?让我给你举个例子,我们来设计一个 *Post*类,我们需要将它分成两个类:*Post*和 *Posts*,单个和多个。我曾在我的一篇文章中提到过,一个好的对象是现实生活中实体的抽象,我们来实践这一原则。我们有两个实体:数据库表和表格行,这就是为什么我们创建两个类:*Post*展示表,*Post*展示行。
我也曾在文章中说过,每个对象应该关联并实现一个接口,让我们先来创建两个接口,当然我们的对象是不可变的,*Posts*应该是这样的:
interface Posts {
Iterable<Post> iterate();
Post add(Date date, String title);
}
单一的 *Post*应该是这样的:
interface Post {
int id();
Date date();
String title();
}
遍历数据库中的所有的post:
Posts posts = // we'll discuss this right now
for (Post post : posts.iterate()){
System.out.println("Title: " + post.title());
}
创建一个新post:
Posts posts = // we'll discuss this right now
posts.add(new Date(), "How to cook an omelette");
你可以看到,我们有真实对象了,他们掌握所有操作,并且在内部隐藏实现细节,没有事务,会话或工厂,我们甚至不知道这些对象是否真的和PostgreSQL交互,或许它只是把数据保存在txt文件中。*Posts*带给我们的是获取post列表和创建新post的能力,具体实现很好地隐藏在其中,现在让我们看一看如何实现这两个类。
我将使用jcabi-jdbc作为JDBC包裹,当然你也可以使用其他你喜欢的JDBC,这无所谓,重点是与数据库的交互要隐藏在对象中,让我们开始实现 *PgPosts*类(“pg”表示PostgreSQL)。
final class PgPosts implements Posts {
private final Source dbase;
public PgPosts(DataSource data) {
this.dbase = data;
}
public Iterable<Post> iterate() {
return new JdbcSession(this.dbase)
.sql("SELECT id FROM post")
.select(
new ListOutcome<Post>(
new ListOutcome.Mapping<Post>() {
@Override
public Post map(final ResultSet rset) {
return new PgPost(
this.dbase,
rset.getInteger(1)
);
}
}
)
);
}
public Post add(Date date, String title) {
return new PgPost(
this.dbase,
new JdbcSession(this.dbase)
.sql("INSERT INTO post (date, title) VALUES (?, ?)")
.set(new Utc(date))
.set(title)
.insert(new SingleOutcome<Integer>(Integer.class))
);
}
}
然后我们创建 *PgPost*类来实现 *Post*接口:
final class PgPost implements Post {
private final Source dbase;
private final int number;
public PgPost(DataSource data, int id) {
this.dbase = data;
this.number = id;
}
public int id() {
return this.number;
}
public Date date() {
return new JdbcSession(this.dbase)
.sql("SELECT date FROM post WHERE id = ?")
.set(this.number)
.select(new SingleOutcome<Utc>(Utc.class));
}
public String title() {
return new JdbcSession(this.dbase)
.sql("SELECT title FROM post WHERE id = ?")
.set(this.number)
.select(new SingleOutcome<String>(String.class));
}
}
下面就是我们用刚刚创建的类来和数据库交互:
Posts posts = new PgPosts(dbase);
for (Post post : posts.iterate()){
System.out.println("Title: " + post.title());
}
Post post = posts.add(new Date(), "How to cook an omelette");
System.out.println("Just added post #" + post.id());
你可以在这看到完整例子.这是一个开源的web app使用PostgreSQL来实现上面提到的-SQL-speaking objects.
性能如何?
我能听到你的惊呼“性能怎么样?”在上面几行代码中,我们创建了和数据库的冗余链接。首先我们用 *SELECT id*来检索post的ID,然后为了获取它们的title,我们对应每个post发送 *SELECT title*请求,这确实效率很低。
不要担心,这是面向对象编程,意味着这是可伸缩的!我们来创建一个 *PgPost*的装饰器,其构造函数接受数据,并在内部缓存:
final class ConstPost implements Post {
private final Post origin;
private final Date dte;
private final String ttl;
public ConstPost(Post post, Date date, String title) {
this.origin = post;
this.dte = date;
this.ttl = title;
}
public int id() {
return this.origin.id();
}
public Date date() {
return this.dte;
}
public String title() {
return this.ttl;
}
}
注意:这个装饰器并不知道PostgreSQL或JDBC,它仅仅是 *POST*对象的装饰,并缓存数据和title。通常,这个装饰器是不可变的。
现在我们来创建 *Posts*的另一个实现,其返回一个”不可变”的对象:
final class ConstPgPosts implements Posts {
// ...
public Iterable<Post> iterate() {
return new JdbcSession(this.dbase)
.sql("SELECT * FROM post")
.select(
new ListOutcome<Post>(
new ListOutcome.Mapping<Post>() {
@Override
public Post map(final ResultSet rset) {
return new ConstPost(
new PgPost(
ConstPgPosts.this.dbase,
rset.getInteger(1)
),
Utc.getTimestamp(rset, 2),
rset.getString(3)
);
}
}
)
);
}
}
现在所有post通过这个 *iterate()*方法返回,并且从数据库中取到了数据装配在新的类中。
使用装饰器和对相同接口的众多实现,你可以组合任意的功能,最重要的是扩展功能的同时,不要增加设计的复杂度,因为类的大小不会增长,我们使用新的高聚合的类,它们更小巧。
事务又如何?
每个对象应该在其单独的事务中执行,并且将 *SELECT*和 *INSERT*封装在一起,这需要内置事务,数据库提供非常棒的支持。如果没有这样的支持,创建一个会话事务对象必须接受一个”callable”类,比如:
final class Txn {
private final DataSource dbase;
public <T> T call(Callable<T> callable) {
JdbcSession session = new JdbcSession(this.dbase);
try {
session.sql("START TRANSACTION").exec();
T result = callable.call();
session.sql("COMMIT").exec();
return result;
} catch (Exception ex) {
session.sql("ROLLBACK").exec();
throw ex;
}
}
}
然后,当你想在一个事务中进行一系列的操作,像下面这样:
new Txn(dbase).call(
new Callable<Integer>() {
@Override
public Integer call() {
Posts posts = new PgPosts(dbase);
Post post = posts.add(new Date(), "How to cook an omelette");
posts.comments().post("This is my first comment!");
return post.id();
}
}
);
这段代码会创建一个新的post并提交一个comment.如果任何调用失败,整个事务将回滚。
对于我来说,这就是面向对象,我称它为”SQL-speaking objects”,因为它们知道如何与数据库服务器通过SQL交互,这是它们的能力,完美封装在其内部。