适合初学入门
第一课 构造数据
本节基本了解Pandas里的一些数据结构和模块的基本使用,初步了解Pandas的提供的一些功能,学会基本使用。
创建数据
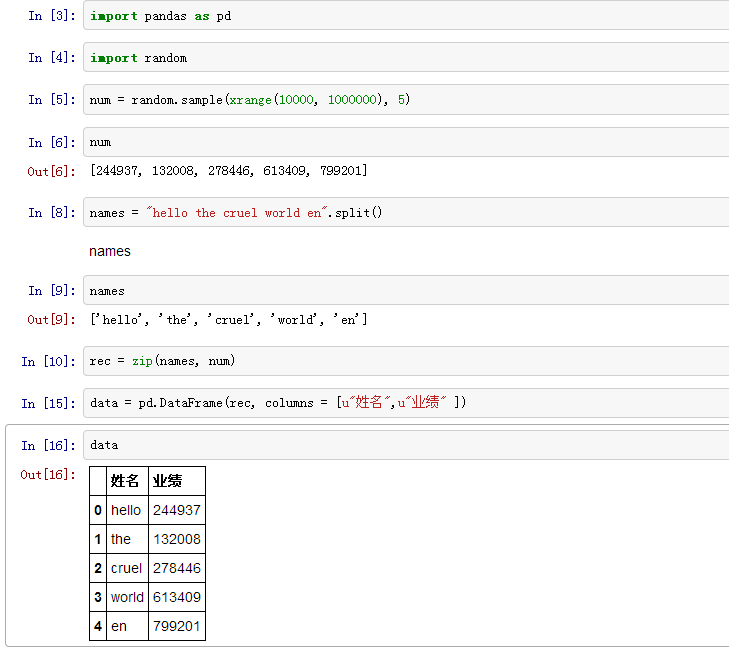
通过Python的zip构造出一元组组成的列表作为DataFrame的输入数据rec。
In [3]: import pandas as pd
In [4]: import random
In [5]: num = random.sample(xrange(10000, 1000000), 5)
In [6]: num
Out[6]: [244937, 132008, 278446, 613409, 799201]
In [8]: names = "hello the cruel world en".split()
In [9]: names
Out[9]: ['hello', 'the', 'cruel', 'world', 'en']
In [10]: rec = zip(names, num)
In [15]: data = pd.DataFrame(rec, columns = [u"姓名",u"业绩" ])
In [16]: data
Out[16]:
姓名 业绩
0 hello 244937
1 the 132008
2 cruel 278446
3 world 613409
4 en 799201
DataFrame方法函数的第一个参数是数据源,第二个参数columns是输出数据表的表头,或者说是表格的字段名。
导出数据csv
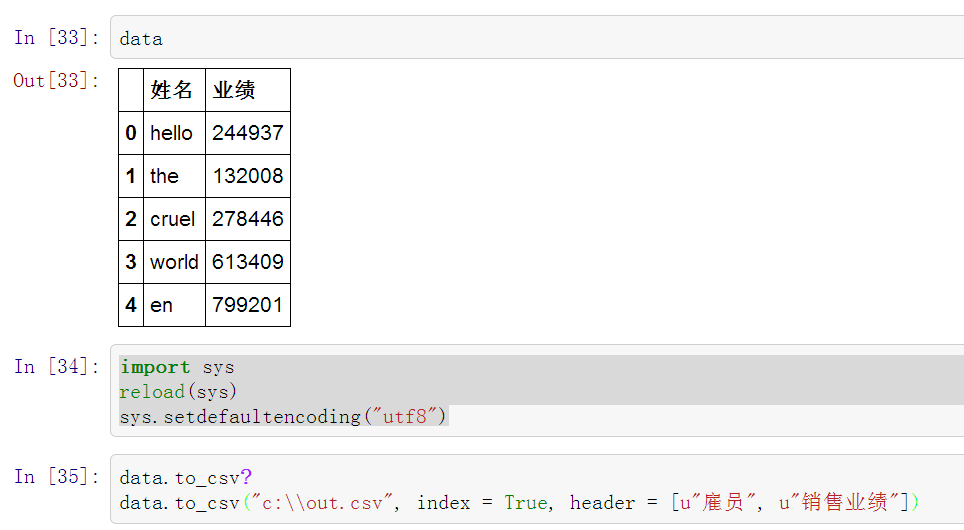
Windows平台上的编码问题,我们可以先做个简单处理,是ipython-notebook支持utf8.
import sys
reload(sys)
sys.setdefaultencoding("utf8")
接下来可以数据导出了。
In [31]: data
Out[31]:
姓名 业绩
0 hello 244937
1 the 132008
2 cruel 278446
3 world 613409
4 en 799201
#在ipython-note里后加问号可查帮助,q退出帮助
In [32]: data.to_csv?
In [33]: data.to_csv("c:\\out.csv", index = True, header = [u"雇员", u"销售业绩"])
将data导出到out.csv文件里,index参数是指是否有主索引,header如果不指定则是以data里columns为头,如果指定则是以后边列表里的字符串为表头,但要注意的是header后的字符串列表的个数要和data里的columns字段个数相同。
可到c盘用Notepad++打开out.csv看看。
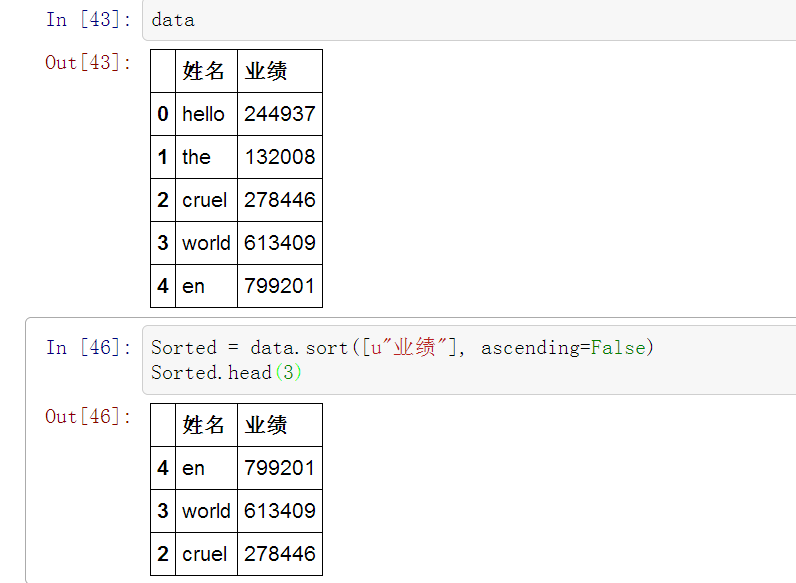
简单的数据分析
In [43]: data
Out[43]:
姓名 业绩
0 hello 244937
1 the 132008
2 cruel 278446
3 world 613409
4 en 799201
#排序并取前三名
In [46]: Sorted = data.sort([u"业绩"], ascending=False)
Sorted.head(3)
Out[46]:
姓名 业绩
4 en 799201
3 world 613409
2 cruel 278446
图形输出
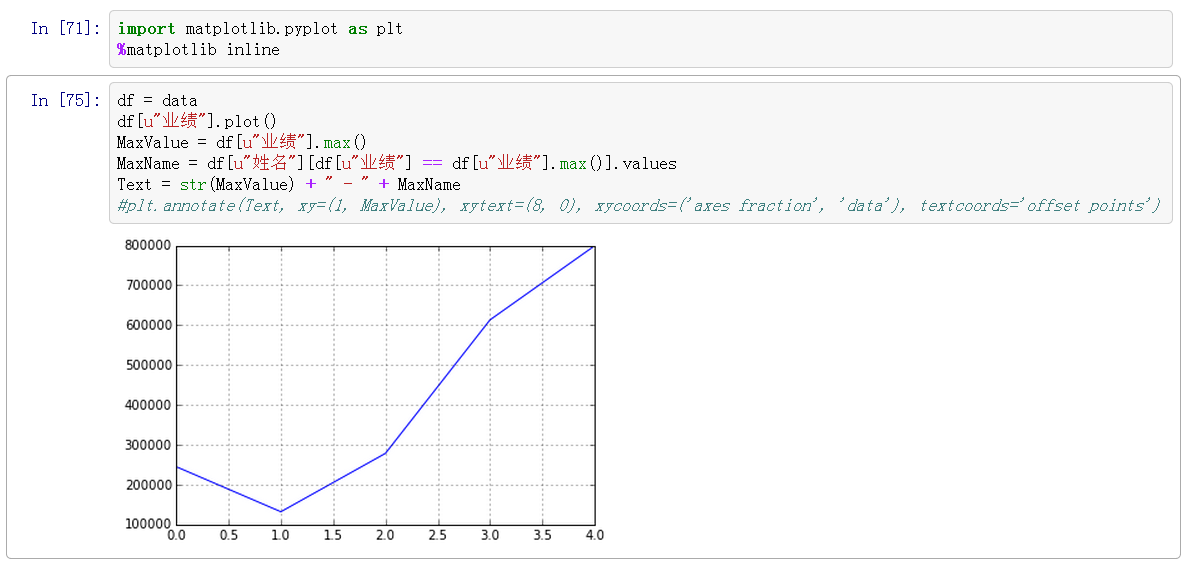
In [71]: import matplotlib.pyplot as plt
#使ipython-notebook支持matplotlib绘图
%matplotlib inline
In [74]: df = data
#绘图
df[u"业绩"].plot()
MaxValue = df[u"业绩"].max()
MaxName = df[u"姓名"][df[u"业绩"] == df[u"业绩"].max()].values
Text = str(MaxValue) + " - " + MaxName
#给图添加文本标注
plt.annotate(Text, xy=(1, MaxValue), xytext=(8, 0), xycoords=('axes fraction', 'data'), textcoords='offset points')
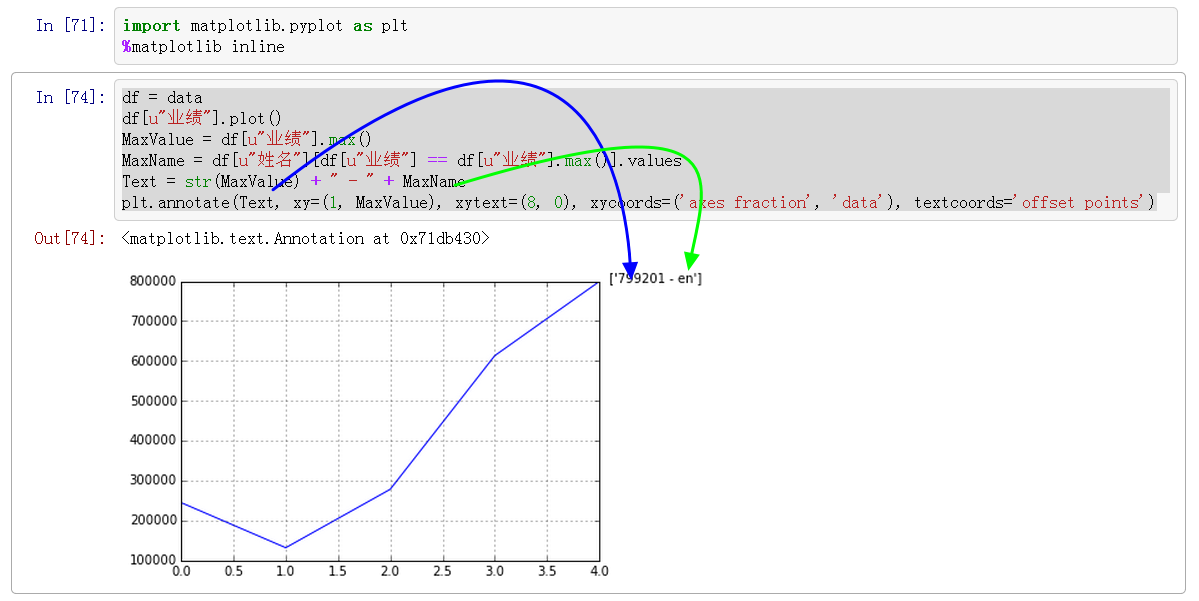 如果注释掉plt.annotate这行,结果如下所示:
如果注释掉plt.annotate这行,结果如下所示: