前言
异常处理的问题之一是知道何时以及如何去使用它。我会讨论一些异常处理的最佳实践,也会总结最近在异常处理上的一些争论。
作为程序员,我们想要写高质量的能够解决问题的代码。但是,异常经常是伴随着代码产生的副作用。没有人喜欢副作用,因此我们会试图用自己的方式来解决这个问题。我看过不少的程序用下面的方法应对异常:
public void consumeAndForgetAllExceptions(){
try {
...some code that throws exceptions
} catch (Exception ex){
ex.printStacktrace();
}
}
上面这段代码的问题在哪里?
一旦一个异常被抛出之后,正常的执行流程会停止并且将控制交给捕捉块。捕捉块捕获异常,然后只是把它的信息打印了一下。之后程序正常运行,就像没有任何事情发生一样。
那下面的这种方法呢?
public void someMethod() throws Exception{
}
这是一个空方法,里面没有任何的代码。为什么一个空方法能够抛出异常?JAVA并不阻止你这么做。最近,我遇到了一些和这个很相似的代码,明明代码块中没有抛出异常的语句,却在方法声明中抛出异常。当我问开发人员为什么这么做,他会回答“我知道这样会影响API,但是我之前就这么做的而且效果还不错”。
C++社区花了好久才决定如何使用异常。这场争论也在JAVA社区产生了。我看到不少JAVA开发人员艰难的使用异常。如果不能够正确使用的话,异常会影响程序的性能,因为它需要使用内存和CPU来创建,抛出以及捕获。如果过度使用的话,会使得代码难以阅读,并且影响API的使用人员。我们都知道这将会带来代码漏洞以及坏味道。客户端代码常会通过忽略这个异常或是直接将其抛出来避开这个问题,就像之前的两个例子那样。
异常的本质
从广义的角度来说,一共有三种不同的场景会导致异常的产生:
- 编程错误导致的异常:这一类的异常是因为不恰当的编程带来的(比如
NullPointerException,IllegalArgumentException)。客户端通常无法对这些错误采取任何措施 - 客户端代码的错误:客户端代码在API允许的范围之外使用API,从而违背了合约。客户端可以通过异常中提供的有用信息,采用一些替代方法。比如,当解析格式不正确的XML文件时,会抛出异常。这个异常中包含导致该错误发生的XML内容的具体位置。客户端可以通过这些信息采取回复措施。
- 资源失效导致的异常:比如系统内存不足或是网络连接失败。客户端面对资源失效的回应是要根据上下文来决定的。客户端可以在一段时间之后试着重新连接或是记录资源失效日志然后暂停应用程序。
JAVA异常类型
JAVA定义了两种异常:
- 需检查的异常:从
Exception类继承的异常都是需检查异常。客户端需要处理API抛出的这一类异常,通过try-catch或是继续抛出。 - 无需检查的异常:
RuntimeException也是Exception的子类。但是,继承了RuntimeException的类受到了特殊的待遇。客户端代码无需专门处理这一类异常。
下图展示了NullPointerException的继承树: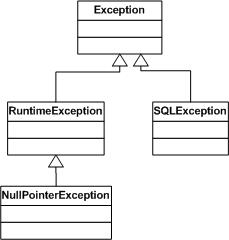
上图中,NullPointerException继承自RuntimeException,因此它也是一个无需检查的异常。
我看到过大量使用需检查异常只在极少数时候使用无需检查异常的。最近,JAVA社区在需检查异常的真正价值上爆发了热烈的讨论。这场辩论源于JAVA是第一个包含需检查异常的主流OO框架。C++和C#根本没有需检查异常。这些语言中所有的异常都是无需检查的。
从低层抛出的需检查异常强制要求调用方捕获或是抛出该异常。如果客户端不能有效的处理该异常,API和客户端之间的异常协议将会带来极大的负担。客户端的开发人员可能会通过将异常抑制在一个空的捕获块中或是直接抛出它。从而又将这个负担交给了客户端的调用方。
还有人指责需检查异常会破坏封装,看下面这段代码:
public List getAllAccounts() throws
FileNotFoundException, SQLException{
...
}
getAllAccounts()方法抛出了两个需检查异常。调用这个方法的客户端必须明确的处理这两种具体的异常,即使它们并不清楚getAllAccount()内究竟是哪个文件访问或是数据库访问失败了,而且它们也没有提供文件系统或是数据库的逻辑。因此,这样的异常处理导致方法和调用者之前出现了不当的强耦合。
设计API的最佳实践
在讨论了这些之后,我们可以来探讨一下如何设计一个正确抛出异常的良好的API。
1.在选择抛出需确定异常或是无需确定异常时,问自己这样的一个问题:客户端代码在遇到异常时会进行怎样的处理?如果客户端能够采取措施从这个异常中恢复过来,那就选择需确定异常。如果客户端不能采取有效的措施,就选择无需确定异常。有效的措施是指从异常中恢复的措施,而不仅仅是记录错误日志。
除此以外,尽量选择无需确定的异常:它的优点在于不会强迫客户端显式地处理这种异常。它会冒泡到任何你想捕获它的地方。JAVA API提供了许多无需检查的异常如NullPointerException, IllegalArgumentException和IllegalStateException。我倾向于使用JAVA提供的标准的异常,尽量不去创建自己的异常。
2.保留封装永远不要将特定于实现的异常传递到更高层。比如,不要将数据层的SQLException传递出去。业务层不需要了解SQLException。你有两个选择:
- 将
SQLException转换为另一个需检查异常,如果客户代码需要从异常中恢复。 - 将
SQLException转换为无需检查异常,如果客户端代码无法对其进行处理。
大多数时候,客户代码无法解决SQLException。这时候就将其转化为无需检查的异常。
public void dataAccessCode(){
try{
..some code that throws SQLException
}catch(SQLException ex){
ex.printStacktrace();
}
}
这里的catch块并没有做任何事情。不如通过如下的方式解决它:
public void dataAccessCode(){
try{
..some code that throws SQLException
}catch(SQLException ex){
throw new RuntimeException(ex);
}
}
这里将SQLException转化为了RuntimeException。如果SQLException出现了,catch块就会抛出一个运行时异常。当前执行的线程将会停止并报告该异常。但是,该异常并没有影响到我的业务逻辑模块,它无需进行异常处理,更何况它根本无法对SQLException进行任何操作。如果我的catch块需要根异常原因,可以使用getCause()方法。
如果你确信业务层可以采取补救措施,你可以将其转化为一个更有意义的无需检查异常。但是我觉得抛出RuntimeException足以适用大多数的场景。
3.当无法提供更加有用信息时,不要自定义异常下面这段代码有什么问题?
public class DuplicateUsernameException
extends Exception {}
它没有给客户端代码提供任何有用的信息,除了一个稍微具有含义的命名。不要忘了Exception类和别的类一样,在里面你可以添加一下方法供客户端调用,获得有用的信息。
public class DuplicateUsernameException
extends Exception {
public DuplicateUsernameException
(String username){....}
public String requestedUsername(){...}
public String[] availableNames(){...}
}
新版本的异常提供了两个有用的方法:requestedUsername(),它会返回请求的名字,和availableNames(),它会返回一组相近的可用的用户名。客户端可以使用这些方法来获取有用的信息。但是如果你不准备添加这些额外的信息,那就抛出一个标准的异常即可。
throw new Exception("Username already taken");
如果你觉得客户端代码在记录日志之外对这个异常不能进行任何操作,那么最好抛出无需检查异常:
throw new RuntimeException("Username already taken");
除此以外,你还可以提供一个方法来检查用户名是否已经被使用。
4.文档化异常你可以使用Javadoc的@throws标记来记录需检查异常和无需检查异常。但是,我倾向于写单元测试来文档化异常。单元测试允许我在使用中查看异常,并且作为一个可以被执行的文档来使用。无论你采用哪种方法,尽量使你的客户端代码了解你的API会抛出的异常。这里提供了IndexOutOfBoundsException的单元测试。
public void testIndexOutOfBoundsException() {
ArrayList blankList = new ArrayList();
try {
blankList.get(10);
fail("Should raise an IndexOutOfBoundsException");
} catch (IndexOutOfBoundsException success) {}
}
上面这段代码在调用blankList.get(10);应当抛出IndexOutOfBoundsException。如果没有抛出该异常,则会执行fail("Should raise an IndexOutOfBoundsException");显式的说明该测试失败了。通过为异常编写测试,你不仅能记录异常如何触发,而且使你的代码在经过这些测试后更加健壮。
使用异常的最佳实践
1.自觉清理资源
如果你在使用如数据库连接或是网络连接之类的资源,要确保你及时的清理这些资源。如果你调用的API仅仅出发了无需检查异常,你仍然需要在使用后主动清理。使用try-catch块。
public void dataAccessCode(){
Connection conn = null;
try{
conn = getConnection();
..some code that throws SQLException
}catch(SQLException ex){
ex.printStacktrace();
} finally{
DBUtil.closeConnection(conn);
}
}
class DBUtil{
public static void closeConnection
(Connection conn){
try{
conn.close();
} catch(SQLException ex){
logger.error("Cannot close connection");
throw new RuntimeException(ex);
}
}
}
DBUtil类关闭Connection连接。这里的重点在于在finally块中关闭连接,无论是否出现了异常。
2.永远不要使用异常来控制流
生成栈追踪的代价很昂贵,它的价值在于debug过程中使用。在一个流程控制中,栈追踪应当被忽视,因为客户端只想知道如何进行。
在下面的代码中,MaximumCountReachedException被用来进行流程控制:
public void useExceptionsForFlowControl() {
try {
while (true) {
increaseCount();
}
} catch (MaximumCountReachedException ex) {
}
//Continue execution
}
public void increaseCount()
throws MaximumCountReachedException {
if (count >= 5000)
throw new MaximumCountReachedException();
}
useExceptionsForFlowControl()通过无限循环来增加计数,直到抛出异常。这种方式使得代码难以阅读,而且影响代码性能。只在出现异常的场景抛出异常。
3.不要无视或是压制异常
当API的方法会抛出异常的时候,它在提醒你应当采取一些措施。如果需检查异常没有任何意义,那就干脆将其转化为无需检查异常再重新抛出。不要单纯的用catch捕获它然后继续执行,仿佛什么都没有发生一样。
4.不要捕获最高层异常
继承RuntimeException的异常同样是Exception的子类。捕获Exception的同时,也捕获了运行时异常:
try{
..
}catch(Exception ex){
}
5.只记录异常一次
将同一个异常多次记入日志会使得检查追踪栈的开发人员感到困惑,不知道何处是报错的根源。所以只记录一次。