在报表项目中,有些报表的数据计算方法会经常改变。例如:某企业员工的实际工资是通过绩效得分计算出的,算法经常变动,需要在不改动其他代码的情况下用新算法替换旧算法。如果用Java来实现计算的话,虽然可以实现动态可挂接计算模块,但是存在缺乏基础类库、占用多余内存等问题。
采用润乾集算报表可以很好的解决这些问题,实现低耦合、热部署的动态挂接算法。集算报表挂接算法系统结合和其他报表工具+java的系统结构对比图如下:
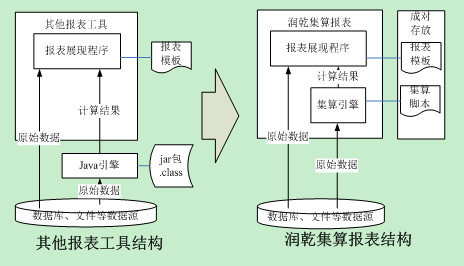
上图可以看出,java程序必须要编译、打包才能更新。集算脚本是解释执行的,脚本文件同时也是可执行文件,所以可以直接替换文件更新。同时,集算脚本可以和报表模板成对存放,可以方便管理。
下面通过员工绩效工资的例子看看集算报表的实现方法,并和一般报表工具+Java的实现方式做一下比较。
员工绩效工资报表如下:
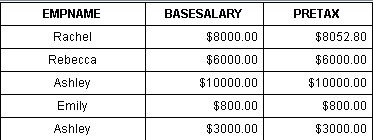
报表格式比较简单,但是计算方法相对复杂,而且经常变动。用集算报表实现可挂接算法的第一步,编写集算器脚本:
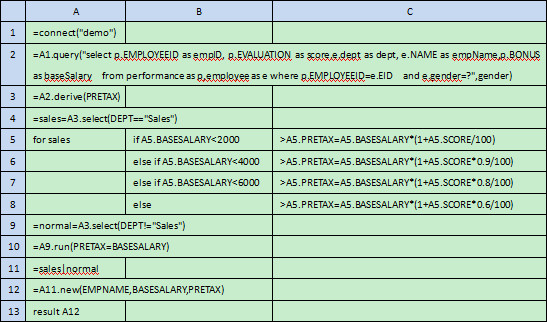
A2单元格有个输入参数gender,是来自用户在报表页面上的选择输入。A13单元格是将结果返回给报表页面。A2到A12之间是绩效工资的计算方法,不是本文重点,这里不详细介绍。
集算报表的报表模板可以定义计算数据集来调用这个可挂接计算模块:
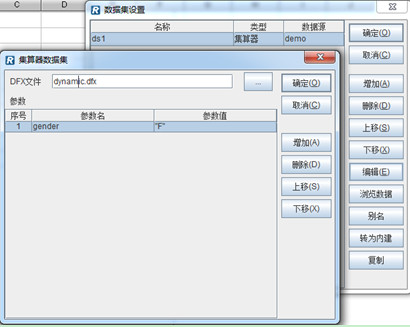
其中,gender参数是dynamic.dfx的输入参数,数据集ds1接收dynamic.dfx返回的结果集。
可以看到集算器脚本dynamic.dfx和报表模板之间的耦合程度非常低。如果要改变绩效工资的计算方法,只需要编写一个新的dynamic.dfx,替换服务器上原有的dfx文件即可。因为dfx脚本是解释执行的,所以可以不停机替换,实现真正的热部署。
最后,在集算报表设计器中设计报表模板如下:
从这个例子可以看出集算报表实现的可挂接算法,相比普通报表工具+Java的实现方式有多方面的优势。
1、dynamic.dfx中可能会用集算报表提供的多种类库:分组、汇总、排序、过滤、关联、唯一值、交集、排名等等。Java程序员必须手工编写这些基础算法。将这些基础算法直接实现在业务逻辑中显然是不合理的,这会导致每个计算模块重复书写类似的代码,计算模块过于庞大、可读性变差。理想的作法是先实现一套基础算法类库,再在计算模块中调用这些类库,但应用程序员很难设计出完备性和系统性优秀的基础算法类库,常常使代码的耦合性高,稳定性差,最终导致计算模块维护困难。
集算报表中集算引擎本身就是这样一套精心设计的完备基础类库,只需要JAVA十分之一的代码量就可以实现同样功能的计算模块,开发效率更高。
2、JAVA代码需要重新编译,部署起来比较麻烦;当可挂接的计算模块较多时,不论是否还要使用它们,这些Java class/jar都会占据内存空间而无法释放,对性能有一定的影响。
集算报表的集算器引擎主程序和脚本文件是分开的,耦合性很低,维护起来更加方便。另外,集算脚本无需编译即可使用,是真正的热部署。脚本程序不会事先加载到内存,而是使用时再加载,计算完立刻释放,不会长期占用内存。