Netty是一个异步事件驱动的网络应用框架,它适用于高性能协议的服务端和客户端的快速开发和维护。其架构如下所示:
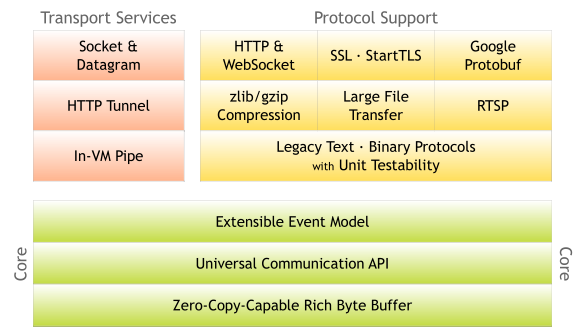
其核心分为三部分,
最低层为支持零拷贝功能的自定义Byte buffer;
中间层为通用通信API;
上层为可扩展的事件模型。
现在我们从最低层的支持零拷贝功能的自定义Byte buffer开始,它包含在io.netty.buffer包内。
io.netty.buffer 包描述:
io.netty.buffer 包中包含了Netty底层的数据结构。
在java nio中byteBuffer表现了底层二进制和文本信息的基础数据结构,io.netty.buffer抽象了byteBuffer api,netty使用自己的Buffer API去提供NIO的byteBuffer来表示字节序列。它的buffer Api跟使用ByteBuffer相比有显著的优势。netty的buffer类型:byteBuf的设计从根本上解决了byteBuffer出现的问题,并且满足了网络应用开发者的日常需求。下面列举一些比较酷的特性:
可以根据自身需求定义自己的buffer类型
透明的零拷贝时通过内置的复合buffer类型来实现。
像StringBuffer一样,支持动态buffer类型根据需要扩展buffer容量。
不再需要调用flip()方法。
通常情况比ByteBuffer更快。
扩展性更好
ByteBuf为优化快速协议实现提供,它提供了丰富的一组操作。例如,它提供了多种操作方式去获取unsigned 值和string及对于buffer中的特定字节序列的检索,你亦可以通过扩展或者包装已经存在的Buffer类型来增加更便利的获取方法。自定义的Buffer类型仍然要继承自ByteBuf接口而不是引进一个不兼容的新类型。
透明的零拷贝
为了提升网络应用的性能到极致,你需要降低内存复制操作进行的次数。当然你也可以设置一组可以切分的buffer,用它们来组合中一个完整的消息。Netty提供了一个组合buffer,这个组合buffer支持你从任意数目的已存在bufer中不使用内存拷贝来创建一个新的buffer。例如,一个消息由两部分组成:头部和内容。在一个模块化的应用中,当发送消息时,这两部分可以有不同模块产生和后面的组合。
+--------+----------+ | header | body | +--------+----------+
若你使用ByteBuffer(java NIO),你必须创建一个新的大的Buffer,然后将这头部和内容拷贝到新创建的buffer中,或者你可以在NIO中使用写操作集中操作,但若你使用复合Buffer作为一个ByteBuffer数组而不是仅仅一个Buffer时,破坏了抽象类型并且引入了一个复杂的状态管理。而且,若你不从NIO channel中读取或者写入时就不会起作用。
//组合类型和组件类型不匹配
ByteBuffer[] message = new ByteBuffer[] { header, body };
相反,ByteBuf没有这种问题,因为它的高扩展性和内置的组合buffer类型。
//组合类型和组件类型不匹配 ByteBuf message = Unpooled.wrappedBuffer(header, body); //因此,你可以通过混和一个组合buffer和一个普通buffer创建一个组合buffer ByteBuf messageWithFooter = Unpooled.wrappedBuffer(message, footer); //由于组合buffer仍然是一个ByteBuf,你可以很容易的获取它的内容,即便你要获取的区域跨越多个组件,和获取简单Buffer的获取方式也是一样的。 //实例中获取的unsigned整型跨越了内容和尾部。 messageWithFooter.getUnsignedInt( messageWithFooter.readableBytes() - footer.readableBytes() - 1);
容量自动扩充(Automatic Capacity Extension)
许多协议定义了消息的长度,这意味着在创建消息之前没法决定消息的长度或者不容易精确计算消息的长度。就像你刚开始创建一个string一样。我们通常估计字符串的长度,然后使用StringBuffer来根据需要去扩充。
//创建新的动态buffer。在内部,为避免潜在的浪费内存空间,真正的buffer将延后创建。
ByteBuf b = Unpooled.buffer(4);
//当第一次尝试去写的时候,才会在内部创建一个容量为4的buffer
b.writeByte('1');
b.writeByte('2');
b.writeByte('3');
b.writeByte('4');
//当要写的字节数超过初始化的容量4时,在内部,buffer自动重新分配一个更大的容量
b.writeByte('5');
更好的性能
在绝大部分情况下,继承自ByteBuf的buffer实现对字节数组(例如byte[])的包装是非常轻量级的。不像ByteBuffer,ByteBuf没有复杂的边界检查和索引补偿,因而,对JVM来说,更容易优化获取buffer的方式。
更复杂的buffer实现仅仅用在切分或者组合buffer,并且复杂buffer的性能和ByteBuffer一样。
ByteBuf的继承关系
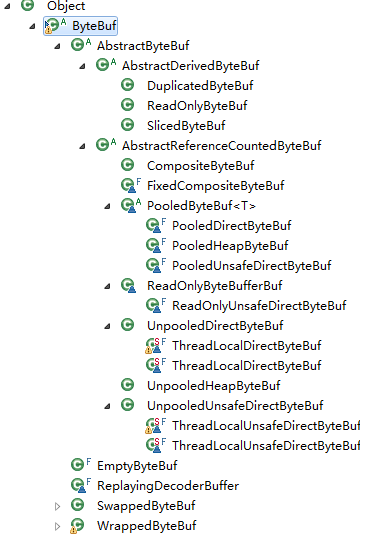
进入ByteBuf来看:
Byte提供了对字节序列的随机或者顺序获取方式,可以读取0个或者多个字节。
这个接口提供了对一个或者多个基本字节数组(byte[])和普通的NIO ByteBuffer的抽象试图。
创建一个Buffer
建议通过使用helper方法unpooled来创建一个新的buffer,而不是调用一个buffer实现的构造方法。
索引的随机访问
同普通的字节数组一样,ByteBuf使用基于0的索引方法,这意味着字节数组的第一个字节的索引为0,数组的最后一个字节索引为容量-1.例如,为便利一个buffer的所有字节,不用考虑它的内部实现,你可以这样做:
buffer = ...;
for (int i = 0; i < buffer.capacity(); i ++) {
byte b = buffer.getByte(i);
System.out.println((char) b);
}
索引的顺序获取
ByteBuf提供了两个指针来支持顺序读取和写入:readerIndex()用来读操作,writerIndex()用来写操作。下图展示了一个buffer是如何通过2个指针来划分为3个区域的:
+-------------------+------------------+------------------+
| 可丢弃字节 | 可读字节 | 可写字节 |
| | (内容) | |
+-------------------+-------------- +------------------+
| | | |
0 <= 读索引 <= 写索引 <= 容量
可读字节(真正的内容)
这个部分是数据真正存储的区域,名称以read或者skip开头的所有操作都会从当前的读索引处读或者跳过数据,并且根据读的字节数目递增。若读操作的参数同样是一个ByteBuf并且没有指明目的索引,指定buffer的写索引将同步增加。
如果下面没有内容了(接着读取就会报越界异常),buffer新分配的默认值或者复制的buffer的可读索引为0.
//遍历一个buffer的可读字节
buffer = ...;
while (buffer.readable()) {
System.out.println(buffer.readByte());
}
可写字节
这个区域是需要填充的未定义空间。以write结尾的任何操作将在当前可写索引处写入数据,并根据写入的字节数目增加可写索引。若写操作的参数是ByteBuf,并且没有指明源索引,指定的Buffer 的可读索引同步增加。
若没有可写入的内容(继续的话会报越界异常)时,Buffer的默认值的写索引是buffer的容量。
// 用任意的整型来填充buffer的可写区域.
{@link ByteBuf} buffer = ...;
while (buffer.maxWritableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
可丢弃的字节
这个区域包含了读操作已经读过了的字节。初始化时该区域的容量为0,但当读操作进行时它的容量会逐渐达到写索引。通过调用discardReadBytes()方法来声明不用区域,如下图描述所示:
discardReadBytes()方法前: * +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity * * discardReadBytes()方法后 * * +------------------+--------------------------------------+ * | readable bytes | writable bytes (got more space) | * +------------------+--------------------------------------+ * | | | * readerIndex (0) <= writerIndex (decreased) <= capacity
请注意:在调用discardReadBytes()方法后,无法保证可些字节的内容。可写字节在大部分情况下不会移动,甚至可以根据不同buffer实现填充完全不同的数据。
清除buffer索引
你可以通过调用clear()方法来设置readerIndex()和writerIndex()的值为0.clear()方法并没有清除buffer中的内容而仅仅是将两个指针的值设为0.请注意:ByteBuf的clear()方法的语法和ByteBuffer的clear()操作时完全不同的。
* clear()调用前 * * +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity * * * clear()调用后 * * +---------------------------------------------------------+ * | writable bytes (got more space) | * +---------------------------------------------------------+ * | | * 0 = readerIndex = writerIndex <= capacity
检索操作:
对简单的单字节检索,使用indexOf()、bytesBefore()。bytesBefore()在处理null(结尾字符)时特别有用。
对于复杂的检索,使用ForEachByte()。
标签 和重置
每个buffer都有两个索引标签。一个用来存储readerIndex,另一个用来存储writerIndex()。你也可以通过调用reset方法来重新设置这两个索引的位置。
除了没有readLimit的inputStream的标签和重置方法也同样起作用。
源buffer
可以通过调用duplicate()或者slice方法来创建一个已经存在buffer的视图。源buffer拥有独立的readerIndex、writeIndex和标签索引,然而像NIO buffer那样,共享别的一些内部数据。
当需要完全拷贝一个已经存在buffer时,请调用copy()方法.
转换到已存在的JDK类型
字节数组
判断一个buffer是否由字节数组组成,使用hasArray()方法判断;
若一个buffer由字节数组构成,可以直接通过array()方法获取;
NIO buffer
判断一个buffer是否可以转换成NIO的buffer,使用nioBufferCount()判断
若一个ByteBuf可以转换成NIO的byteBuffer,可以通过nioBuffer方法获取。
字符串
将ByteBuf转换成string的toString方法有很多个,请一定注意:toString不是一个转换方法。
I/O流
请参考byteBufInputStream和ByteBufOutputStream.
小结:
Netty底层的数据结构为ByteBuf接口及其实现,抓住它们就获取到了底层实现的精华,本文仅是针对ByteBuf做简单介绍,其实现类还需要读者自己去慢慢摸索 。